ЧоҪьРҙЕАіжКұРиТӘУГөҪХэФтұнҙпКҪЈ¬УР¶ОКұјдГ»УРК№УГХэФтұнҙпКҪПЦФЪҪҘҪҘёРҫхУРР©өӯНьЈ¬ПЦФЪК№УГ»№РиТӘИҘІйСҜТ»Р©ЧКБП
ОӘБЛұЬГвТФәуХвСщөДЗйҝцЈ¬ФЪҙЛјЗВјПВХэФтұнҙпКҪөДТ»Р©»щұҫК№УГ·Ҫ·ЁёҪҙшРЎөДКөАэЎЈИГТФәуФЪК№УГКұДЬТ»ДҝБЛИ»ЦӘөАЛыөДК№УГЈ¬ОӘҝӘ·ўҪЪФјКұјдЈ¬Н¬КұТІ·ЦПнёшҙујТ
ХэФтФӘЧЦ·ы
ЎЎЎЎФЪЛөХэФтұнҙпКҪЦ®З°ОТГЗПИАҙҝҙҝҙНЁЕд·ыЈ¬ОТПлНЁЕд·ыҙујТ¶јУГ№эЎЈНЁЕд·ыЦчТӘУРРЗәЕ(*)әНОКәЕ(?)Ј¬УГАҙДЈәэЛСЛчОДјюЎЈwinodwsЦРОТГЗіЈ»бК№УГЛСЛчАҙІйХТТ»Р©ОДјюЎЈИз:*.jpgЈ¬XXX.docxөД·ҪКҪЈ¬АҙҝмЛЩІйХТОДјюЎЈЖдКөХэФтұнҙпКҪәНОТГЗНЁЕд·ыәЬПаЛЖТІКЗНЁ№эМШ¶ЁөДЧЦ·ыЖҘЕдОТГЗЛщТӘІйСҜөДДЪИЭРЕПўЎЈТСПВҙъВл¶јКЗЗш·ЦҙуРЎРҙЎЈ
іЈУГФӘЧЦ·ы
| ҙъВл |
ЛөГч |
| . |
ЖҘЕдіэ»»РР·ыТФНвөДИОТвЧЦ·ыЎЈ |
| \w |
ЖҘЕдЧЦДё»тКэЧЦ»тПВ»®ПЯ»тәәЧЦЎЈ |
| \s |
ЖҘЕдИОТвөДҝХ°Ч·ыЎЈ |
| \d |
ЖҘЕдКэЧЦЎЈ |
| \b |
ЖҘЕдөҘҙКөДҝӘКј»тҪбКшЎЈ |
| [ck] |
ЖҘЕд°ьә¬АЁәЕДЪФӘЛШөДЧЦ·ы |
| ^ |
ЖҘЕдРРөДҝӘКјЎЈ |
| $ |
ЖҘЕдРРөДҪбКшЎЈ |
| \ |
¶ФПВТ»ёцЧЦ·ыЧӘТеЎЈұИИз$КЗёцМШКвөДЧЦ·ыЎЈТӘЖҘЕд$өД»°ҫНөГУГ\$ |
| | |
·ЦЦ§МхјюЈ¬ИзЈәx|yЖҘЕд x »т yЎЈ |
·ҙТеФӘЧЦ·ы
| ҙъВл |
ЛөГч |
| \W |
ЖҘЕдИОТвІ»КЗЧЦДёЈ¬КэЧЦЈ¬ПВ»®ПЯЈ¬әәЧЦөДЧЦ·ыЎЈ |
| \S |
ЖҘЕдИОТвІ»КЗҝХ°Ч·ыөДЧЦ·ыЎЈөИјЫУЪ [^ \f\n\r\t\v]ЎЈ |
| \D |
ЖҘЕдИОТв·ЗКэЧЦөДЧЦ·ыЎЈөИјЫУЪ [^0-9]ЎЈ |
| \B |
ЖҘЕдІ»КЗөҘҙКҝӘН·»тҪбКшөДО»ЦГЎЈ |
| [^CK] |
ЖҘЕдіэБЛCKТФНвөДИОТвЧЦ·ыЎЈ |
МШКвФӘЧЦ·ы
| ҙъВл |
ЛөГч |
| \f |
ЖҘЕдТ»ёц»»Ті·ыЎЈөИјЫУЪ \x0c әН \cLЎЈ |
| \n |
ЖҘЕдТ»ёц»»РР·ыЎЈөИјЫУЪ \x0a әН \cJЎЈ |
| \r |
ЖҘЕдТ»ёц»Шіө·ыЎЈөИјЫУЪ \x0d әН \cMЎЈ |
| \t |
ЖҘЕдТ»ёцЦЖұн·ыЎЈөИјЫУЪ \x09 әН \cIЎЈ |
| \v |
ЖҘЕдТ»ёцҙ№ЦұЦЖұн·ыЎЈөИјЫУЪ \x0b әН \cKЎЈ |
ПЮ¶Ё·ы
| ҙъВл |
ЛөГч |
| * |
ЖҘЕдЗ°ГжөДЧУұнҙпКҪБгҙО»т¶аҙОЎЈ |
| + |
ЖҘЕдЗ°ГжөДЧУұнҙпКҪТ»ҙО»т¶аҙОЎЈ |
| ? |
ЖҘЕдЗ°ГжөДЧУұнҙпКҪБгҙО»тТ»ҙОЎЈ |
| {n} |
n КЗТ»ёц·ЗёәХыКэЎЈЖҘЕдИ·¶ЁөД n ҙОЎЈ |
| {n,} |
n КЗТ»ёц·ЗёәХыКэЎЈЦБЙЩЖҘЕдn ҙОЎЈ |
| {n,m} |
m әН n ҫщОӘ·ЗёәХыКэЈ¬ЖдЦРn <= mЎЈЧоЙЩЖҘЕд n ҙОЗТЧо¶аЖҘЕд m ҙОЎЈ |
АБ¶иПЮ¶Ё·ы
| ҙъВл |
ЛөГч |
| *? |
ЦШёҙИОТвҙОЈ¬ө«ҫЎҝЙДЬЙЩЦШёҙЎЈ
Из "acbacb" ХэФт "a.*?b" Ц»»бИЎөҪөЪТ»ёц"acb" ФӯұҫҝЙТФИ«ІҝИЎөҪө«јУБЛПЮ¶Ё·ыәуЈ¬Ц»»бЖҘЕдҫЎҝЙДЬЙЩөДЧЦ·ы Ј¬¶ш"acbacb"ЧоЙЩЧЦ·ыөДҪб№ыҫНКЗ"acb" ЎЈ
|
| +? |
ЦШёҙ1ҙО»тёь¶аҙОЈ¬ө«ҫЎҝЙДЬЙЩЦШёҙЎЈУлЙПГжТ»СщЈ¬Ц»КЗЦБЙЩТӘЦШёҙ1ҙОЎЈ |
| ?? |
ЦШёҙ0ҙО»т1ҙОЈ¬ө«ҫЎҝЙДЬЙЩЦШёҙЎЈ
Из "aaacb" ХэФт "a.??b" Ц»»бИЎөҪЧоәуөДИэёцЧЦ·ы"acb"ЎЈ
|
| {n,m}? |
ЦШёҙnөҪmҙОЈ¬ө«ҫЎҝЙДЬЙЩЦШёҙЎЈ
Из "aaaaaaaa" ХэФт "a{0,m}" ТтОӘЧоЙЩКЗ0ҙОЛщТФИЎөҪҪб№ыОӘҝХЎЈ
|
| {n,}? |
ЦШёҙnҙОТФЙПЈ¬ө«ҫЎҝЙДЬЙЩЦШёҙЎЈ
Из "aaaaaaa" ХэФт "a{1,}" ЧоЙЩКЗ1ҙОЛщТФИЎөҪҪб№ыОӘ "a"ЎЈ
|
І¶»с·ЦЧй
| ҙъВл |
ЛөГч |
| (exp) |
ЖҘЕдexp,ІўІ¶»сОДұҫөҪЧФ¶ҜГьГыөДЧйАпЎЈ |
| (?<name>exp) |
ЖҘЕдexp,ІўІ¶»сОДұҫөҪГыіЖОӘnameөДЧйАпЎЈ |
| (?:exp) |
ЖҘЕдexp,І»І¶»сЖҘЕдөДОДұҫЈ¬ТІІ»ёшҙЛ·ЦЧй·ЦЕдЧйәЕТФПВОӘБгҝн¶ПСФЎЈ |
| (?=exp) |
ЖҘЕдexpЗ°ГжөДО»ЦГЎЈ
Из "How are you doing" ХэФт"(?<txt>.+(?=ing))" ХвАпИЎingЗ°ЛщУРөДЧЦ·ыЈ¬Іў¶ЁТеБЛТ»ёцІ¶»с·ЦЧйГыЧЦОӘ "txt" ¶ш"txt"ХвёцЧйАпөДЦөОӘ"How are you do";
|
| (?<=exp) |
ЖҘЕдexpәуГжөДО»ЦГЎЈ
Из "How are you doing" ХэФт"(?<txt>(?<=How).+)" ХвАпИЎ"How"Ц®әуЛщУРөДЧЦ·ыЈ¬Іў¶ЁТеБЛТ»ёцІ¶»с·ЦЧйГыЧЦОӘ "txt" ¶ш"txt"ХвёцЧйАпөДЦөОӘ" are you doing";
|
| (?!exp) |
ЖҘЕдәуГжёъөДІ»КЗexpөДО»ЦГЎЈ
Из "123abc" ХэФт "\d{3}(?!\d)"ЖҘЕд3О»КэЧЦәу·ЗКэЧЦөДҪб№ы
|
| (?<!exp) |
ЖҘЕдЗ°ГжІ»КЗexpөДО»ЦГЎЈ
Из "abc123 " ХэФт "(?<![0-9])123" ЖҘЕд"123"З°ГжКЗ·ЗКэЧЦөДҪб№ыТІҝЙРҙіЙ"(?!<\d)123"
|
өГөҪЙПГжГШј®әуОТГЗҝЙТФРЎКФЕЈө¶...
РЎКФЕЈө¶
ФЪC#ЦРК№УГХэФтұнҙпКҪЦчТӘКЗНЁ№эRegexАаАҙКөПЦЎЈГьГыҝХјдЈәusing System.Text.RegularExpressionsЎЈ
ЖдЦРіЈУГ·Ҫ·ЁЈә
| ГыіЖ |
ЛөГч |
| IsMatch(String, String) |
ЦёКҫ Regex №№ФмәҜКэЦРЦё¶ЁөДХэФтұнҙпКҪФЪЦё¶ЁөДКдИлЧЦ·ыҙ®ЦРКЗ·сХТөҪБЛЖҘЕдПоЎЈ |
| Match(String, String) |
ФЪЦё¶ЁөДКдИлЧЦ·ыҙ®ЦРЛСЛч Regex №№ФмәҜКэЦРЦё¶ЁөДХэФтұнҙпКҪөДөЪТ»ёцЖҘЕдПоЎЈ |
| Matches(String, String) |
ФЪЦё¶ЁөДКдИлЧЦ·ыҙ®ЦРЛСЛчХэФтұнҙпКҪөДЛщУРЖҘЕдПоЎЈ |
| Replace(String, String) |
ФЪЦё¶ЁөДКдИлЧЦ·ыҙ®ДЪЈ¬К№УГЦё¶ЁөДМж»»ЧЦ·ыҙ®Мж»»УлДіёцХэФтұнҙпКҪДЈКҪЖҘЕдөДЛщУРЧЦ·ыҙ®ЎЈ |
| Split(String, String) |
ФЪУЙ Regex №№ФмәҜКэЦё¶ЁөДХэФтұнҙпКҪДЈКҪЛщ¶ЁТеөДО»ЦГЈ¬Ір·ЦЦё¶ЁөДКдИлЧЦ·ыҙ®ЎЈ |
ФЪК№УГХэФтұнҙпКҪЗ°ОТГЗПИАҙҝҙҝҙЎ°@Ўұ·ыәЕөДК№УГЎЈ
С§№эC#өДИЛ¶јЦӘөАC# ЦРЧЦ·ыҙ®іЈБҝҝЙТФТФ@ ҝӘН·ЙщГыЈ¬ХвСщөДУЕөгКЗЧӘТеРтБРЎ°І»Ўұұ»ҙҰАнЈ¬°ҙЎ°ФӯСщЎұКдіцЈ¬јҙОТГЗІ»РиТӘ¶ФЧӘТеЧЦ·ыјУЙП \ ЈЁ·ҙРұҝёЈ©Ј¬ҫНҝЙТФЗбЛЙcodingЎЈИз:
string filePath = @"c:\Docs\Source\CK.txt" // rather than "c:\\Docs\\Source\\CK.txt"
ИзТӘФЪТ»ёцУГ @ ТэЖрАҙөДЧЦ·ыҙ®ЦР°ьАЁТ»ёцЛ«ТэәЕЈ¬ҫНРиТӘК№УГБҪ¶ФЛ«ТэәЕБЛЎЈХвКұәтДгІ»ДЬК№УГ \ АҙЧӘТеЛ¬ТэәЕБЛЈ¬ТтОӘФЪХвАп \ өДЧӘТеУГНҫТСҫӯұ» @ Ў°ЖБұОЎұөфБЛЎЈИз:
string str=@"""Ahoy!"" cried the captain." // КдіцОӘЈә "Ahoy!" cried the captain.
ЧЦ·ыҙ®ЖҘЕдЈә
ФЪКөјКПоДҝЦРОТГЗіЈіЈРиТӘ¶ФУГ»§КдИлөДРЕПўҪшРРСйЦӨЎЈИзЈәЖҘЕдУГ»§КдИлөДДЪИЭКЗ·сОӘКэЧЦЈ¬КЗ·сОӘУРР§өДКЦ»ъәЕВлЈ¬УКПдКЗ·сәП·Ё....өИЎЈ
КөАэҙъВлЈә
string RegexStr = string.Empty;
#region ЧЦ·ыҙ®ЖҘЕд
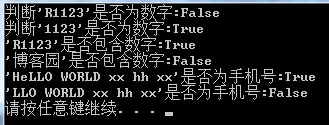
RegexStr = "^[0-9]+$"; //ЖҘЕдЧЦ·ыҙ®өДҝӘКјәНҪбКшКЗ·сОӘ0-9өДКэЧЦ[¶ЁО»ЧЦ·ы]
Console.WriteLine("ЕР¶П'R1123'КЗ·сОӘКэЧЦ:{0}", Regex.IsMatch("R1123", RegexStr));
Console.WriteLine("ЕР¶П'1123'КЗ·сОӘКэЧЦ:{0}", Regex.IsMatch("1123", RegexStr));
RegexStr = @"\d+"; //ЖҘЕдЧЦ·ыҙ®ЦРјдКЗ·с°ьә¬КэЧЦ(ХвАпГ»УРҙУҝӘКјҪшРРЖҘЕдаЮ,ИОТвО»ЧУЦ»ТӘУРТ»ёцКэЧЦјҙҝЙ)
Console.WriteLine("'R1123'КЗ·с°ьә¬КэЧЦ:{0}", Regex.IsMatch("R1123", RegexStr));
Console.WriteLine("'І©ҝНФ°'КЗ·с°ьә¬КэЧЦ:{0}", Regex.IsMatch("І©ҝНФ°", RegexStr));
//ёРР»@zhoumyөДМбРС..ТСРЮёДҙнОуҙъВл
RegexStr = @"^Hello World[\w\W]*"; //ТСHello WorldҝӘН·өДИОТвЧЦ·ы(\w\WЈәЧйәПҝЙЖҘЕдИОТвЧЦ·ы)
Console.WriteLine("'HeLLO WORLD xx hh xx'КЗ·сТСHello WorldҝӘН·:{0}", Regex.IsMatch("HeLLO WORLD xx hh xx", RegexStr, RegexOptions.IgnoreCase));
Console.WriteLine("'LLO WORLD xx hh xx'КЗ·сТСHello WorldҝӘН·:{0}", Regex.IsMatch("LLO WORLD xx hh xx", RegexStr,RegexOptions.IgnoreCase));
//RegexOptions.IgnoreCaseЈәЦё¶ЁІ»Зш·ЦҙуРЎРҙөДЖҘЕдЎЈ
#endregion
ПФКҫҪб№ыЈә
ЧЦ·ыҙ®ІйХТЈә
КөАэҙъВлЈә
string RegexStr = string.Empty;
#region ЧЦ·ыҙ®ІйХТ
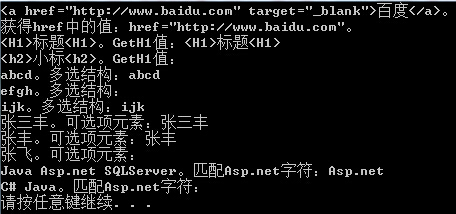
string LinkA = "<a href=\"http://www.baidu.com\" target=\"_blank\">°Щ¶И</a>";
RegexStr = @"href=""[\S]+"""; // ""ЖҘЕд"
Match mt = Regex.Match(LinkA, RegexStr);
Console.WriteLine("{0}ЎЈ", LinkA);
Console.WriteLine("»сөГhrefЦРөДЦөЈә{0}ЎЈ", mt.Value);
RegexStr = @"<h[^23456]>[\S]+<h[1]>"; //<h[^23456]>:ЖҘЕдhіэБЛ2,3,4,5,6Ц®ЦРөДЦө,<h[1]>:hЖҘЕд°ьә¬АЁәЕДЪФӘЛШөДЧЦ·ы
Console.WriteLine("{0}ЎЈGetH1ЦөЈә{1}", "<H1>ұкМв<H1>", Regex.Match("<H1>ұкМв<H1>", RegexStr, RegexOptions.IgnoreCase).Value);
Console.WriteLine("{0}ЎЈGetH1ЦөЈә{1}", "<h2>РЎұк<h2>", Regex.Match("<h2>РЎұк<h2>", RegexStr, RegexOptions.IgnoreCase).Value);
//RegexOptions.IgnoreCase:Цё¶ЁІ»Зш·ЦҙуРЎРҙөДЖҘЕдЎЈ
RegexStr = @"ab\w+|ij\w{1,}"; //ЖҘЕдabәНЧЦДё »т ijәНЧЦДё
Console.WriteLine("{0}ЎЈ¶аСЎҪб№№Јә{1}", "abcd", Regex.Match("abcd", RegexStr).Value);
Console.WriteLine("{0}ЎЈ¶аСЎҪб№№Јә{1}", "efgh", Regex.Match("efgh", RegexStr).Value);
Console.WriteLine("{0}ЎЈ¶аСЎҪб№№Јә{1}", "ijk", Regex.Match("ijk", RegexStr).Value);
RegexStr = @"ХЕИэ?·б"; //?ЖҘЕдЗ°ГжөДЧУұнҙпКҪБгҙО»тТ»ҙОЎЈ
Console.WriteLine("{0}ЎЈҝЙСЎПоФӘЛШЈә{1}", "ХЕИэ·б", Regex.Match("ХЕИэ·б", RegexStr).Value);
Console.WriteLine("{0}ЎЈҝЙСЎПоФӘЛШЈә{1}", "ХЕ·б", Regex.Match("ХЕ·б", RegexStr).Value);
Console.WriteLine("{0}ЎЈҝЙСЎПоФӘЛШЈә{1}", "ХЕ·Й", Regex.Match("ХЕ·Й", RegexStr).Value);
/*
АэИзЈә
July|JulЎЎЎЎҝЙЛх¶МОӘЎЎЎЎJuly?
4th|4ЎЎЎЎ ҝЙЛх¶МОӘЎЎЎЎ4(th)?
*/
//ЖҘЕдМШКвЧЦ·ы
RegexStr = @"Asp\.net"; //ЖҘЕдAsp.netЧЦ·ыЈ¬ТтОӘ.КЗФӘЧЦ·ыЛы»бЖҘЕдіэ»»РР·ыТФНвөДИОТвЧЦ·ыЎЈХвАпОТГЗЦ»РиТӘЛыЖҘЕд.ЧЦ·ыјҙҝЙЎЈЛщТФРиТӘЧӘТе\.ХвСщұнКҫЖҘЕд.ЧЦ·ы
Console.WriteLine("{0}ЎЈЖҘЕдAsp.netЧЦ·ыЈә{1}", "Java Asp.net SQLServer", Regex.Match("Java Asp.net SQLServer", RegexStr).Value);
Console.WriteLine("{0}ЎЈЖҘЕдAsp.netЧЦ·ыЈә{1}", "C# Java", Regex.Match("C# Java", RegexStr).Value);
#endregion
ПФКҫҪб№ыЈә
М°А·УлАБ¶и
string f = "fooot";
//М°А·ЖҘЕд
RegexStr = @"f[o]+";
Match m1 = Regex.Match(f, RegexStr);
Console.WriteLine("{0}М°А·ЖҘЕд(ЖҘЕдҫЎҝЙДЬ¶аөДЧЦ·ы)Јә{1}", f, m1.ToString());
//АБ¶иЖҘЕд
RegexStr = @"f[o]+?";
Match m2 = Regex.Match(f, RegexStr);
Console.WriteLine("{0}АБ¶иЖҘЕд(ЖҘЕдҫЎҝЙДЬЙЩЦШёҙ)Јә{1}", f, m2.ToString());
ПФКҫҪб№ыЈә
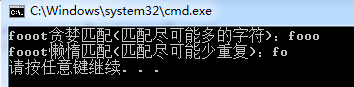
ҙУЙПГжөДАэЧУЦРОТГЗІ»ДСҝҙіцМ°А·УлАБ¶иөДЗшұрЈ¬ЛыГЗөДГыЧУИЎөД¶јәЬРОПуЎЈ
М°А·ЖҘЕдЈәЖҘЕдҫЎҝЙДЬ¶аөДЧЦ·ыЎЈ
АБ¶иЖҘЕдЈәЖҘЕдҫЎҝЙДЬЙЩөДЧЦ·ыЎЈ
(exp)·ЦЧй
ФЪЧцЕАіжКұОТГЗҫӯіЈ»сөГAЦРТ»Р©УРУГРЕПўЎЈИзhref,titleәНПФКҫДЪИЭөИЎЈ
string TaobaoLink = "<a href=\"http://www.taobao.com\" title=\"МФұҰНш - МФЈЎОТПІ»¶\" target=\"_blank\">МФұҰ</a>";
RegexStr = @"<a[^>]+href=""(\S+)""[^>]+title=""([\s\S]+?)""[^>]+>(\S+)</a>";
Match mat = Regex.Match(TaobaoLink, RegexStr);
for (int i = 0; i < mat.Groups.Count; i++)
{
Console.WriteLine("өЪ"+i+"ЧйЈә"+mat.Groups[i].Value);
}
ПФКҫҪб№ыЈә
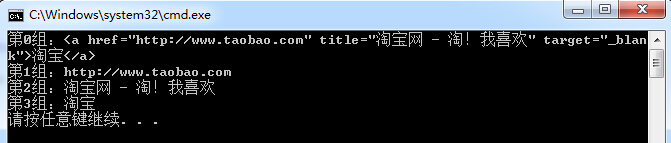
ФЪХэФтұнҙпКҪАпК№УГ()°ьә¬өДОДұҫЧФ¶Ҝ»бГьГыОӘТ»ёцЧйЎЈЙПГжөДұнҙпКҪЦР№ІК№УГБЛ4ёц()ҝЙТФИПОӘКЗ·ЦОӘБЛ4ЧйЎЈ
КдіцҪб№ы№І·ЦОӘЈә4ЧйЎЈ
0ЧйЈәОӘОТГЗЛщЖҘЕдөДЧЦ·ыҙ®ЎЈ
1ЧйЈәКЗОТГЗөЪТ»ёцАЁәЕ[href=""(\S+)""]ЦР(\S+)ЛщЖҘЕдөДНшЦ·РЕПўЎЈДЪИЭОӘЈәhttp://www.taobao.comЎЈ
2ЧйЈәКЗөЪ¶юёцАЁәЕ[title=""([\s\S]+?)""]ЦРЛщЖҘЕдөДДЪИЭРЕПўЎЈДЪИЭОӘЈәМФұҰНш - МФЈЎОТПІ»¶ЎЈ
ХвАпОТГЗ»бҝҙөҪ+?АБ¶иПЮ¶Ё·ыЎЈtitle=""([\s\S]+?)"" ХвАп+?өДПВТ»ёцЧЦ·ыОӘ"Л«ТэәЕЈ¬"Л«ТэәЕФЪЖҘЕдЧЦ·ыҙ®әуГж»№УРИэёцЎЈ+?АБ¶иПЮ¶Ё·ы»бҫЎҝЙДЬЙЩЦШёҙЈ¬ЛщЛы»бЖҘЕдЧоЗ°ГжДЗёц"Л«ТэәЕЎЈИз№ыОТГЗІ»К№УГ+?АБ¶иПЮ¶Ё·ыЛы»бЖҘЕдөҪЈәМФұҰНш - МФЈЎОТПІ»¶" target= »бҫЎҝЙДЬ¶аЦШёҙЖҘЕдЎЈ
3ЧйЈәКЗөЪИэёцАЁәЕ[(\S+)]ЛщЖҘЕдөДДЪИЭРЕПўЎЈДЪИЭОӘЈәМФұҰЎЈ
ЛөГчЈә·ҙТеФӘЧЦ·ыЛщ¶ФУҰөДФӘЧЦ·ы¶јДЬЧйәПЖҘЕдИОТвЧЦ·ыЎЈИз:[\w\W],[\s\S],[\d\D]..
(?<name>exp) ·ЦЧйИЎГы
өұОТГЗЖҘЕд·ЦЧйРЕПў№э¶аәуЈ¬ФЪДіЦЦіЎәПЦ»РиИЎөұЦРДіјёЧйРЕПўЎЈХвКұОТГЗҝЙТФ¶Ф·ЦЧйИЎГыЎЈНЁ№э·ЦЧйГыіЖАҙҝмЛЩМбИЎ¶ФУҰРЕПўЎЈ
string Resume = "»щұҫРЕПўРХГы:CK|ЗуЦ°ТвПт:.NETИнјю№ӨіМКҰ|РФұр:ДР|С§Аъ:ұҫЧЁ|іцЙъИХЖЪ:1988-08-08|»§ј®:әюұұ.РўёР|E - Mail:9245162@qq.com|КЦ»ъ:15000000000";
RegexStr = @"РХГы:(?<name>[\S]+)\|\S+РФұр:(?<sex>[\S]{1})\|С§Аъ:(?<xueli>[\S]{1,10})\|іцЙъИХЖЪ:(?<Birth>[\S]{10})\|[\s\S]+КЦ»ъ:(?<phone>[\d]{11})";
Match matc = Regex.Match(Resume, RegexStr);
Console.WriteLine("РХГыЈә{0},КЦ»ъәЕЈә{1}", matc.Groups["name"].ToString(), matc.Groups["phone"].ToString());
ПФКҫҪб№ыЈә
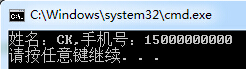
НЁ№э(?<name>exp)ҝЙТФәЬЗбТЧОӘ·ЦЧйИЎГыЎЈИ»әуНЁ№эGroups["name"]ИЎөГ·ЦЧйЦөЎЈ
»сөГТіГжЦРAұкЗ©ЦРhrefЦө
string PageInfo = @"<hteml>
<div id=""div1"">
<a href=""http://www.baidu.con"" target=""_blank"">°Щ¶И</a>
<a href=""http://www.taobao.con"" target=""_blank"">МФұҰ</a>
<a href=""http://www.cnblogs.com"" target=""_blank"">І©ҝНФ°</a>
<a href=""http://www.google.con"" target=""_blank"">google</a>
</div>
<div id=""div2"">
<a href=""/zufang/"">ХыЧв</a>
<a href=""/hezu/"">әПЧв</a>
<a href=""/qiuzu/"">ЗуЧв</a>
<a href=""/ershoufang/"">¶юКЦ·ҝ</a>
<a href=""/shangpucz/"">ЙМЖМіцЧв</a>
</div>
</hteml>";
RegexStr = @"<a[^>]+href=""(?<href>[\S]+?)""[^>]*>(?<text>[\S]+?)</a>";
MatchCollection mc = Regex.Matches(PageInfo, RegexStr);
foreach (Match item in mc)
{
Console.WriteLine("href:{0}--->text:{1}",item.Groups["href"].ToString(),item.Groups["text"].ToString());
}
ПФКҫҪб№ыЈә
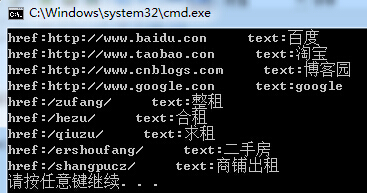
Replace Мж»»ЧЦ·ыҙ®
УГ»§ФЪКдИлРЕПўКұЕј¶ы»б°ьә¬Т»Р©ГфёРҙКЈ¬ХвКұОТГЗРиТӘМж»»ХвёцГфёРҙКЎЈ
string PageInputStr = "ҝҝ.TMMD,ҪсМмХжІ»Л¬....";
RegexStr = @"ҝҝ|TMMD|ВиөД";
Regex rep_regex = new Regex(RegexStr);
Console.WriteLine("УГ»§КдИлРЕПўЈә{0}", PageInputStr);
Console.WriteLine("ТіГжПФКҫРЕПўЈә{0}", rep_regex.Replace(PageInputStr, "***"));
ПФКҫҪб№ыЈә
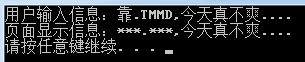
¶ФТ»Р©ГфёРҙКЦұҪУМж»»іЙ***ҙъМжЎЈ
Split Ір·ЦЧЦ·ыҙ®
string SplitInputStr = "1xxxxx.2ooooo.3eeee.4kkkkkk.";
RegexStr = @"\d";
Regex spl_regex = new Regex(RegexStr);
string[] str = spl_regex.Split(SplitInputStr);
foreach (string item in str)
{
Console.WriteLine(item);
}
ПФКҫҪб№ыЈә
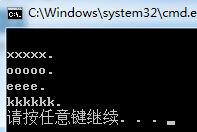
ёщҫЭКэЧЦҪШИЎЧЦ·ыҙ®ЎЈ
КЧПИЈ¬ОТГЗПИҝҙјёёцКөјКөДАэЧУЈә
1Ј® СйЦӨКдИлЧЦ·ыКЗ·с
javascript:
var ex = "^\\w+$";
var re = new RegExp(ex,"i");
return re.test(str);
VBScript
Dim regEx,flag,ex
ex = "^\w+$"
Set regEx = New RegExp
regEx.IgnoreCase = True
regEx.Global = True
regEx.Pattern = ex
flag = regEx.Test( str )
C#
System.String ex = @"^\w+$";
System.Text.RegularExpressions.Regex reg = new Regex( ex );
bool flag = reg.IsMatch( str );
2Ј® СйЦӨУКјюёсКҪ
C#
System.String ex = @"^\w+@\w+\.\w+$";
System.Text.RegularExpressions.Regex reg = new Regex( ex );
bool flag = reg.IsMatch( str );
3Ј® ёьёДИХЖЪөДёсКҪЈЁУГ dd-mm-yy өДИХЖЪРОКҪҙъМж mm/dd/yy өДИХЖЪРОКҪЈ©
C#
String MDYToDMY(String input)
{
return Regex.Replace(input,
"\\b(?\\d{1,2})/(?\\d{1,2})/(?\\d{2,4})\\b",
"${day}-${month}-${year}");
}
4Ј® ҙУ URL МбИЎРӯТйәН¶ЛҝЪәЕ
C#
String Extension(String url)
{
Regex r = new Regex(@"^(?\w+)://[^/]+?(?:\d+)?/",
RegexOptions.Compiled);
return r.Match(url).Result("${proto}${port}");
}
ХвАпөДАэЧУҝЙДЬКЗОТГЗФЪНшТіҝӘ·ўЦРЈ¬НЁіЈ»бЕцөҪөДТ»Р©ХэФтұнҙпКҪЈ¬УИЖдФЪөЪТ»ёцАэЧУЦРЈ¬ёшіцБЛК№УГjavascript,vbScript,C#өИІ»Н¬УпСФөДКөПЦ·ҪКҪЈ¬ҙујТІ»ДСҝҙіцЈ¬¶ФУЪІ»Н¬өДУпСФАҙЛөЈ¬ХэФтұнҙпКҪГ»УРЗшұрЈ¬Ц»КЗХэФтұнҙпКҪөДКөПЦАаІ»Н¬¶шТСЎЈ¶шИзәО·ў»УХэФтұнҙпКҪөД№«УГЈ¬ТІТӘҝҙКөПЦАаөДЦ§іЦЎЈ
ЈЁХӘЧФmsdn: Microsoft .NET ҝтјЬ SDK МṩҙуБҝөДХэФтұнҙпКҪ№ӨҫЯЈ¬К№ДъДЬ№»ёЯР§өШҙҙҪЁЎўұИҪПәНРЮёДЧЦ·ыҙ®Ј¬ТФј°СёЛЩөШ·ЦОцҙуБҝОДұҫәНКэҫЭТФЛСЛчЎўТЖіэәНМж»»ОДұҫДЈКҪЎЈms-help://MS.VSCC/MS.MSDNVS.2052/cpgenref/html/cpconregularexpressionslanguageelements.htmЈ©
ПВГжОТГЗЦрёцАҙ·ЦОцХвР©АэЧУЈә
1-2Ј¬ХвБҪёцАэЧУәЬјтөҘЈ¬Ц»КЗјтөҘөДСйЦӨЧЦ·ыҙ®КЗ·с·ыәПХэФтұнҙпКҪ№ж¶ЁөДёсКҪЈ¬ЖдЦРК№УГөДУп·ЁЈ¬ФЪөЪТ»ЖӘОДХВЦР¶јТСҫӯҪйЙЬ№эБЛЈ¬ХвАпЧцТ»ПВјтөҘөДГиКцЎЈ
өЪ1ёцАэЧУөДұнҙпКҪЈә ^\w+$
^ -- ұнКҫПЮ¶ЁЖҘЕдҝӘКјУЪЧЦ·ыҙ®өДҝӘКј
\w ЁC ұнКҫЖҘЕдУўОДЧЦ·ы
+ -- ұнКҫЖҘЕдЧЦ·ыіцПЦ1ҙО»т¶аҙО
$ -- ұнКҫЖҘЕдЧЦ·ыөҪЧЦ·ыҙ®ҪбОІҙҰҪбКш
СйЦӨРОИзasgasdfsөДЧЦ·ыҙ®
өЪ2ёцАэЧУөДұнҙпКҪЈә ^\w+@\w+.\w+$
^ -- ұнКҫПЮ¶ЁЖҘЕдҝӘКјУЪЧЦ·ыҙ®өДҝӘКј
\w ЁC ұнКҫЖҘЕдУўОДЧЦ·ы
+ -- ұнКҫЖҘЕдЧЦ·ыіцПЦ1ҙО»т¶аҙО
@ -- ЖҘЕдЖХНЁЧЦ·ы@
\. ЁC ЖҘЕдЖХНЁЧЦ·ы.(ЧўТв.ОӘМШКвЧЦ·ы,ТтҙЛТӘјУЙП\ЧӘТл)
$ -- ұнКҫЖҘЕдЧЦ·ыөҪЧЦ·ыҙ®ҪбОІҙҰҪбКш
СйЦӨРОИзdragontt@sina.comөДУКјюёсКҪ
өЪ3 ёцАэЧУЦРЈ¬К№УГБЛМж»»Ј¬ТтҙЛЈ¬ОТГЗ»№КЗПИАҙҝҙҝҙХэФтұнҙпКҪЦРМж»»өД¶ЁТеЈә
ЈЁms-help://MS.VSCC/MS.MSDNVS.2052/cpgenref/html/cpconsubstitutions.htmЈ©
Мж»»
ЧЦ·ы
ә¬Те
$123
Мж»»УЙЧйәЕ 123ЈЁК®ҪшЦЖЈ©ЖҘЕдөДЧоәуТ»ёцЧУЧЦ·ыҙ®ЎЈ
${name}
Мж»»УЙ (? ) ЧйЖҘЕдөДЧоәуТ»ёцЧУЧЦ·ыҙ®ЎЈ
$$
Мж»»өҘёцЎ°$ЎұЧЦ·ыЎЈ
$&
Мж»»НкИ«ЖҘЕдұҫЙнөДТ»ёцёұұҫЎЈ
$`
Мж»»ЖҘЕдЗ°өДКдИлЧЦ·ыҙ®өДЛщУРОДұҫЎЈ
$'
Мж»»ЖҘЕдәуөДКдИлЧЦ·ыҙ®өДЛщУРОДұҫЎЈ
$+
Мж»»Чоә󲶻сөДЧйЎЈ
$_
Мж»»ХыёцКдИлЧЦ·ыҙ®ЎЈ
·ЦЧй№№Фм
ЈЁms-help://MS.VSCC/MS.MSDNVS.2052/cpgenref/html/cpcongroupingconstructs.htmЈ©
·ЦЧй№№Фм
¶ЁТе
( )
І¶»сЖҘЕдөДЧУЧЦ·ыҙ®ЈЁ»т·ЗІ¶»сЧйЈ»УР№Шёь¶аРЕПўЈ¬ЗлІОФДХэФтұнҙпКҪСЎПоЦРөД ExplicitCapture СЎПоЎЈЈ©К№УГ () өДІ¶»сёщҫЭЧуАЁәЕөДЛіРтҙУ 1 ҝӘКјЧФ¶ҜұаәЕЎЈІ¶»сФӘЛШұаәЕОӘБгөДөЪТ»ёцІ¶»сКЗУЙХыёцХэФтұнҙпКҪДЈКҪЖҘЕдөДОДұҫЎЈ
(?<name> )
Ҫ«ЖҘЕдөДЧУЧЦ·ыҙ®І¶»сөҪТ»ёцЧйГыіЖ»тұаәЕГыіЖЦРЎЈУГУЪ name өДЧЦ·ыҙ®І»ДЬ°ьә¬ИОәОұкөг·ыәЕЈ¬ІўЗТІ»ДЬТФКэЧЦҝӘН·ЎЈҝЙТФК№УГөҘТэәЕМжҙъјвАЁәЕЈ¬АэИз (?'name')ЎЈ
(?<name1-name2> )
ЖҪәвЧй¶ЁТеЎЈЙҫіэПИЗ°¶ЁТеөД name2 ЧйөД¶ЁТеІўФЪ name1 ЧйЦРҙжҙўПИЗ°¶ЁТеөД name2 ЧйәНөұЗ°ЧйЦ®јдөДјдёфЎЈИз№ыОҙ¶ЁТе name2 ЧйЈ¬ФтЖҘЕдҪ«»ШЛЭЎЈУЙУЪЙҫіэ name2 өДЧоәуТ»ёц¶ЁТе»бПФКҫ name2 өДПИЗ°¶ЁТеЈ¬ТтҙЛёГ№№ФмФКРнҪ« name2 ЧйөДІ¶»с¶СХ»УГЧчјЖКэЖчТФёъЧЩЗ¶МЧ№№ФмЈЁИзАЁәЕЈ©ЎЈФЪҙЛ№№ФмЦРЈ¬name1 КЗҝЙСЎөДЎЈҝЙТФК№УГөҘТэәЕМжҙъјвАЁәЕЈ¬АэИз (?'name1-name2')ЎЈ
(?: )
·ЗІ¶»сЧйЎЈ
(?imnsx-imnsx: )
УҰУГ»тҪыУГЧУұнҙпКҪЦРЦё¶ЁөДСЎПоЎЈАэИзЈ¬(?i-s: ) Ҫ«ҙтҝӘІ»Зш·ЦҙуРЎРҙІўҪыУГөҘРРДЈКҪЎЈУР№Шёь¶аРЕПўЈ¬ЗлІОФДХэФтұнҙпКҪСЎПоЎЈ
(?= )
Бгҝн¶ИХэФӨІвПИРР¶ПСФЎЈҪцөұЧУұнҙпКҪФЪҙЛО»ЦГөДУТІаЖҘЕдКұІЕјМРшЖҘЕдЎЈАэИзЈ¬\w+(?=\d) УләуёъКэЧЦөДөҘҙКЖҘЕдЈ¬¶шІ»УлёГКэЧЦЖҘЕдЎЈҙЛ№№ФмІ»»б»ШЛЭЎЈ
(?! )
Бгҝн¶ИёәФӨІвПИРР¶ПСФЎЈҪцөұЧУұнҙпКҪІ»ФЪҙЛО»ЦГөДУТІаЖҘЕдКұІЕјМРшЖҘЕдЎЈАэИзЈ¬\b(?!un)\w+\b УлІ»ТФ un ҝӘН·өДөҘҙКЖҘЕдЎЈ
(?<= )
Бгҝн¶ИХэ»Ш№Ләу·ў¶ПСФЎЈҪцөұЧУұнҙпКҪФЪҙЛО»ЦГөДЧуІаЖҘЕдКұІЕјМРшЖҘЕдЎЈАэИзЈ¬(?<=19)99 УлёъФЪ 19 әуГжөД 99 өДКөАэЖҘЕдЎЈҙЛ№№ФмІ»»б»ШЛЭЎЈ
(?
Бгҝн¶Иёә»Ш№Ләу·ў¶ПСФЎЈҪцөұЧУұнҙпКҪІ»ФЪҙЛО»ЦГөДЧуІаЖҘЕдКұІЕјМРшЖҘЕдЎЈ
(?> )
·З»ШЛЭЧУұнҙпКҪЈЁТІіЖОӘМ°А·ЧУұнҙпКҪЈ©ЎЈёГЧУұнҙпКҪҪцНкИ«ЖҘЕдТ»ҙОЈ¬И»әуҫНІ»»бЦр¶ОІОУл»ШЛЭБЛЎЈЈЁТІҫНКЗЛөЈ¬ёГЧУұнҙпКҪҪцУлҝЙУЙёГЧУұнҙпКҪөҘ¶АЖҘЕдөДЧЦ·ыҙ®ЖҘЕдЎЈЈ©
ОТГЗ»№КЗПИјтөҘөДБЛҪвТ»ПВХвБҪёцёЕДоЈә
·ЦЧй№№ФмЈә
Чо»щұҫөД№№Фм·ҪКҪҫНКЗ(),ФЪЧуУТАЁәЕЦРАЁЖрАҙөДІҝ·ЦЈ¬ҫНКЗТ»ёц·ЦЧйЈ»
ёьҪшТ»ІҪөД·ЦЧйҫНКЗРОИзЈә(?<name> )өД·ЦЧй·ҪКҪЈ¬ХвЦЦ·ҪКҪУлөЪТ»ЦЦ·ҪКҪөДІ»Н¬өгЈ¬ҫНКЗ¶Ф·ЦЧйөДІҝ·ЦҪшРРБЛГьГыЈ¬ХвСщҫНҝЙТФНЁ№эёГЧйөДГьГыАҙ»сИЎРЕПўЈ»
ЈЁ»№УРРОИз(?= )өИөИөД·ЦЧй№№ФмЈ¬ОТГЗХвЖӘөДАэЧУЦРТІГ»УРК№УГөҪЈ¬ПВҙООТГЗФЪАҙҪйЙЬЈ©
Мж»»Јә
ЙПГжМбөҪБЛБҪЦЦ»щұҫөД№№Фм·ЦЧй·ҪКҪ()ТФј°(?<name> )Ј¬НЁ№эХвБҪЦЦ·ЦЧй·ҪКҪЈ¬ОТГЗҝЙТФөГөҪРОИз$1,${name}өДЖҘЕдҪб№ыЎЈ
ХвСщЛөЈ¬ҝЙДЬёЕДоЙП»№КЗУРР©ДЈәэЈ¬ОТГЗ»№КЗҪбәПЙПГжөДАэЧУАҙЛөЈә
өЪИэёцАэЧУөДХэФтұнҙпКҪОӘЈә\\b(?\\d{1,2})/(?\\d{1,2})/(?\\d{2,4})\\b
ЈЁҪвКНТ»ПВЈ¬ОӘКІГҙХвАп¶јКЗ\\Т»ЖрУГЈәХвАпКЗC#өДАэЧУЈ¬ФЪC#УпСФЦР\КЗЧӘТлЧЦ·ыЈ¬ТӘПлЧЦ·ыҙ®ЦРөД\І»ЧӘТлЈ¬ҫНРиТӘК№УГ\\»тХЯФЪХыёцЧЦ·ыҙ®өДҝӘКјјУЙП@ұкјЗЈ¬јҙЙПГжөИјЫУл
@Ўұ\b(?\d{1,2})/(?\d{1,2})/(?\d{2,4}\bЎұЈ©
\b -- КЗТ»ЦЦМШКвЗйҝцЎЈФЪХэФтұнҙпКҪЦРЈ¬іэБЛФЪ [] ЧЦ·ыАаЦРұнКҫНЛёс·ыТФНвЈ¬\b ұнКҫЧЦұЯҪзЈЁФЪ \w әН \W ЧЦ·ыЦ®јдЈ©ЎЈФЪМж»»ДЈКҪЦРЈ¬\b КјЦХұнКҫНЛёс·ы
(?\d{1,2}) ЁC №№ФмТ»ёцГыОӘmonthөД·ЦЧйЈ¬Хвёц·ЦЧйЖҘЕдТ»ёціӨ¶ИОӘ1-2өДКэЧЦ
/ -- ЖҘЕдЖХНЁөД/ЧЦ·ы
(?\d{1,2}) --№№ФмТ»ёцГыОӘdayөД·ЦЧйЈ¬Хвёц·ЦЧйЖҘЕдТ»ёціӨ¶ИОӘ1-2өДКэЧЦ
/ -- ЖҘЕдЖХНЁөД/ЧЦ·ы
(?\d{2,4}\bЎұЈ© --№№ФмТ»ёцГыОӘyearөД·ЦЧйЈ¬Хвёц·ЦЧйЖҘЕдТ»ёціӨ¶ИОӘ2-4өДКэЧЦ
ХвАп»№І»ДЬ№»ҝҙіцХвР©·ЦЧйөДЧчУГЈ¬ОТГЗҪУЧЕҝҙХвТ»ҫд
${day}-${month}-${year}
${day} ЁC »сөГЙПГж№№ФмөДГыОӘdayөД·ЦЧйЖҘЕдәуөДРЕПў
- -- ЖХНЁөД-ЧЦ·ы
${month} --»сөГЙПГж№№ФмөДГыОӘmonthөД·ЦЧйЖҘЕдәуөДРЕПў
- -- ЖХНЁөД-ЧЦ·ы
${year} --»сөГЙПГж№№ФмөДГыОӘyearөД·ЦЧйЖҘЕдәуөДРЕПў
ҫЩАэАҙЛөЈә
Ҫ«РОИз04/02/2003өДИХЖЪК№УГАэ3ЦЦөД·Ҫ·ЁМж»»
(?\d{1,2}) ·ЦЧйҪ«ЖҘЕдөҪ04УЙ${month}өГөҪХвёцЖҘЕдЦө
(?\d{1,2}) ·ЦЧйҪ«ЖҘЕдөҪ02УЙ${day}өГөҪХвёцЖҘЕдЦө
(?\d{1,2}) ·ЦЧйҪ«ЖҘЕдөҪ2003УЙ${year}өГөҪХвёцЖҘЕдЦө
БЛҪвБЛХвёцАэЧУәуЈ¬ОТГЗФЪАҙҝҙөЪ4ёцАэЧУҫНәЬјтөҘБЛЎЈ
өЪ4ёцАэЧУөДХэФт
^(?\w+)://[^/]+?(?:\d+)?/
^ -- ұнКҫПЮ¶ЁЖҘЕдҝӘКјУЪЧЦ·ыҙ®өДҝӘКј
(?\w+) ЁC №№ФмТ»ёцГыОӘprotoөД·ЦЧйЈ¬ЖҘЕдТ»ёц»т¶аёцЧЦДё
: -- ЖХНЁөД:ЧЦ·ы
// -- ЖҘЕдБҪёц/ЧЦ·ы
[^/] ЁC ұнКҫХвАпІ»ФКРнКЗ/ЧЦ·ы
+? ЁC ұнКҫЦё¶ЁҫЎҝЙДЬЙЩөШК№УГЦШёҙө«ЦБЙЩК№УГТ»ҙОЖҘЕд
(?:\d+) ЁC №№ФмТ»ёцГыОӘportөД·ЦЧйЈ¬ЖҘЕдРОИз:2134ЈЁГ°әЕ+Т»ёц»т¶аёцКэЧЦЈ©
? ЁC ұнКҫЖҘЕдЧЦ·ыіцПЦ0ҙО»т1ҙО
/ -- ЖҘЕд/ЧЦ·ы
ЧоәуНЁ№э${proto}${port}Аҙ»сИЎБҪёц·ЦЧй№№ФмөДЖҘЕдДЪИЭ
ЈЁУР№ШRegex¶ФПуөДУГ·ЁЈ¬ІОҝј
ms-help://MS.VSCC/MS.MSDNVS.2052/cpref/html/frlrfSystemTextRegularExpressionsRegexMembersTopic.htmЈ©
| 




