РЕПўФЪјЖЛг»ъЙПКЗУГ¶юҪшЦЖұнКҫөДЈ¬ХвЦЦұнКҫ·ЁИГИЛАнҪвҫНәЬА§ДСЎЈТтҙЛјЖЛг»ъЙП¶јЕдУРКдИләНКдіцЙиұёЈ¬ХвР©ЙиұёөДЦчТӘДҝөДҫНКЗЈ¬ТФТ»ЦЦИЛАаҝЙФД¶БөДРОКҪҪ«РЕПў ФЪХвР©ЙиұёЙППФКҫіцАҙ№©ИЛФД¶БАнҪв
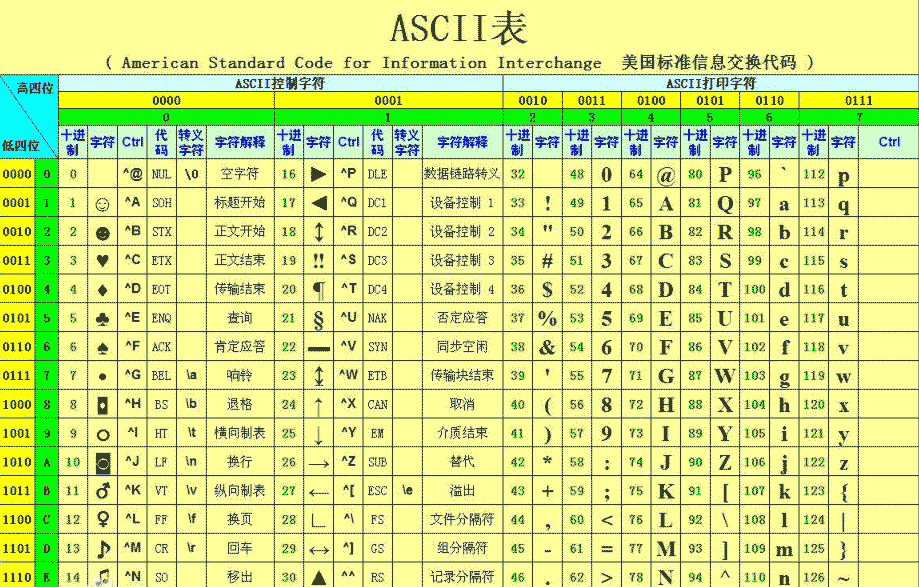
ASCIIВлұн
РЕПўФЪјЖЛг»ъЙПКЗУГ¶юҪшЦЖұнКҫөДЈ¬ХвЦЦұнКҫ·ЁИГИЛАнҪвҫНәЬА§ДСЎЈТтҙЛјЖЛг»ъЙП¶јЕдУРКдИләНКдіцЙиұёЈ¬ХвР©ЙиұёөДЦчТӘДҝөДҫНКЗЈ¬ТФТ»ЦЦИЛАаҝЙФД¶БөДРОКҪҪ«РЕПў ФЪХвР©ЙиұёЙППФКҫіцАҙ№©ИЛФД¶БАнҪвЎЈОӘұЈЦӨИЛАаәНЙиұёЈ¬ЙиұёәНјЖЛг»ъЦ®јдДЬҪшРРХэИ·өДРЕПўҪ»»»Ј¬ИЛГЗұаЦЖөДНіТ»өДРЕПўҪ»»»ҙъВлЈ¬ХвҫНКЗASCIIВлұнЈ¬ЛьөДИ«іЖКЗЎ°ГА№ъРЕПўҪ»»»ұкЧјҙъВлЎұЎЈ
| °ЛҪшЦЖ |
К®БщҪшЦЖ |
К®ҪшЦЖ |
ЧЦ·ы |
°ЛҪшЦЖ |
К®БщҪшЦЖ |
К®ҪшЦЖ |
ЧЦ·ы |
| 00 |
00 |
0 |
nul |
100 |
40 |
64 |
@ |
| 01 |
01 |
1 |
soh |
101 |
41 |
65 |
A |
| 02 |
02 |
2 |
stx |
102 |
42 |
66 |
B |
| 03 |
03 |
3 |
etx |
103 |
43 |
67 |
C |
| 04 |
04 |
4 |
eot |
104 |
44 |
68 |
D |
| 05 |
05 |
5 |
enq |
105 |
45 |
69 |
E |
| 06 |
06 |
6 |
ack |
106 |
46 |
70 |
F |
| 07 |
07 |
7 |
bel |
107 |
47 |
71 |
G |
| 10 |
08 |
8 |
bs |
110 |
48 |
72 |
H |
| 11 |
09 |
9 |
ht |
111 |
49 |
73 |
I |
| 12 |
0a |
10 |
nl |
112 |
4a |
74 |
J |
| 13 |
0b |
11 |
vt |
113 |
4b |
75 |
K |
| 14 |
0c |
12 |
ff |
114 |
4c |
76 |
L |
| 15 |
0d |
13 |
er |
115 |
4d |
77 |
M |
| 16 |
0e |
14 |
so |
116 |
4e |
78 |
N |
| 17 |
0f |
15 |
si |
117 |
4f |
79 |
O |
| 20 |
10 |
16 |
dle |
120 |
50 |
80 |
P |
| 21 |
11 |
17 |
dc1 |
121 |
51 |
81 |
Q |
| 22 |
12 |
18 |
dc2 |
122 |
52 |
82 |
R |
| 23 |
13 |
19 |
dc3 |
123 |
53 |
83 |
S |
| 24 |
14 |
20 |
dc4 |
124 |
54 |
84 |
T |
| 25 |
15 |
21 |
nak |
125 |
55 |
85 |
U |
| 26 |
16 |
22 |
syn |
126 |
56 |
86 |
V |
| 27 |
17 |
23 |
etb |
127 |
57 |
87 |
W |
| 30 |
18 |
24 |
can |
130 |
58 |
88 |
X |
| 31 |
19 |
25 |
em |
131 |
59 |
89 |
Y |
| 32 |
1a |
26 |
sub |
132 |
5a |
90 |
Z |
| 33 |
1b |
27 |
esc |
133 |
5b |
91 |
[ |
| 34 |
1c |
28 |
fs |
134 |
5c |
92 |
\ |
| 35 |
1d |
29 |
gs |
135 |
5d |
93 |
] |
| 36 |
1e |
30 |
re |
136 |
5e |
94 |
^ |
| 37 |
1f |
31 |
us |
137 |
5f |
95 |
_ |
| 40 |
20 |
32 |
sp |
140 |
60 |
96 |
' |
| 41 |
21 |
33 |
! |
141 |
61 |
97 |
a |
| 42 |
22 |
34 |
" |
142 |
62 |
98 |
b |
| 43 |
23 |
35 |
# |
143 |
63 |
99 |
c |
| 44 |
24 |
36 |
$ |
144 |
64 |
100 |
d |
| 45 |
25 |
37 |
% |
145 |
65 |
101 |
e |
| 46 |
26 |
38 |
& |
146 |
66 |
102 |
f |
| 47 |
27 |
39 |
` |
147 |
67 |
103 |
g |
| 50 |
28 |
40 |
( |
150 |
68 |
104 |
h |
| 51 |
29 |
41 |
) |
151 |
69 |
105 |
i |
| 52 |
2a |
42 |
* |
152 |
6a |
106 |
j |
| 53 |
2b |
43 |
+ |
153 |
6b |
107 |
k |
| 54 |
2c |
44 |
, |
154 |
6c |
108 |
l |
| 55 |
2d |
45 |
- |
155 |
6d |
109 |
m |
| 56 |
2e |
46 |
. |
156 |
6e |
110 |
n |
| 57 |
2f |
47 |
/ |
157 |
6f |
111 |
o |
| 60 |
30 |
48 |
0 |
160 |
70 |
112 |
p |
| 61 |
31 |
49 |
1 |
161 |
71 |
113 |
q |
| 62 |
32 |
50 |
2 |
162 |
72 |
114 |
r |
| 63 |
33 |
51 |
3 |
163 |
73 |
115 |
s |
| 64 |
34 |
52 |
4 |
164 |
74 |
116 |
t |
| 65 |
35 |
53 |
5 |
165 |
75 |
117 |
u |
| 66 |
36 |
54 |
6 |
166 |
76 |
118 |
v |
| 67 |
37 |
55 |
7 |
167 |
77 |
119 |
w |
| 70 |
38 |
56 |
8 |
170 |
78 |
120 |
x |
| 71 |
39 |
57 |
9 |
171 |
79 |
121 |
y |
| 72 |
3a |
58 |
: |
172 |
7a |
122 |
z |
| 73 |
3b |
59 |
; |
173 |
7b |
123 |
{ |
| 74 |
3c |
60 |
< |
174 |
7c |
124 |
| |
| 75 |
3d |
61 |
= |
175 |
7d |
125 |
} |
| 76 |
3e |
62 |
> |
176 |
7e |
126 |
~ |
| 77 |
3f |
63 |
? |
177 |
7f |
127 |
del |
»ШіөЎў»»РРЎўҝХёсөДASCIIВлЦөЎӘЈЁёҪASCIIВлұнЈ©
»ШіөЈ¬ASCIIВл13Ј¬"\r"
»»РРЈ¬ASCIIВл10Ј¬"\n"
ҝХёсЈ¬ASCIIВл32
Return = CR = 13 = '\x0d'
NewLine = LF = 10 = '\x0a'
»Шіө·ыәЕәН»»РР·ыәЕІъЙъұіҫ°
№ШУЪЎ°»ШіөЎұЈЁcarriage returnЈ©әНЎ°»»РРЎұЈЁline feedЈ©ХвБҪёцёЕДоөДАҙАъәНЗшұрЎЈ
ФЪјЖЛг»ъ»№Г»УРіцПЦЦ®З°Ј¬УРТ»ЦЦҪРЧцөзҙ«ҙтЧЦ»ъЈЁTeletype Model 33Ј©өДНжТвЈ¬ГҝГлЦУҝЙТФҙт10ёцЧЦ·ыЎЈө«КЗЛьУРТ»ёцОКМвЈ¬ҫНКЗҙтНкТ»РР»»РРөДКұәтЈ¬ТӘУГИҘ0.2ГлЈ¬ХэәГҝЙТФҙтБҪёцЧЦ·ыЎЈТӘКЗФЪХв0.2ГлАпГжЈ¬УЦУРРВөДЧЦ·ыҙ«№эАҙЈ¬ДЗГҙХвёцЧЦ·ыҪ«¶ӘК§ЎЈ
УЪКЗЈ¬СРЦЖИЛФұПлБЛёц°м·ЁҪвҫцХвёцОКМвЈ¬ҫНКЗФЪГҝРРәуГжјУБҪёцұнКҫҪбКшөДЧЦ·ыЎЈТ»ёцҪРЧцЎ°»ШіөЎұЈ¬ёжЛЯҙтЧЦ»ъ°СҙтУЎН·¶ЁО»ФЪЧуұЯҪзЈ»БнТ»ёцҪРЧцЎ°»»РРЎұЈ¬ёжЛЯҙтЧЦ»ъ°СЦҪПтПВТЖТ»РРЎЈ
ХвҫНКЗЎ°»»РРЎұәНЎ°»ШіөЎұөДАҙАъЈ¬ҙУЛьГЗөДУўУпГыЧЦЙПТІҝЙТФҝҙіцТ»¶юЎЈ
әуАҙЈ¬јЖЛг»ъ·ўГчБЛЈ¬ХвБҪёцёЕДоТІҫНұ»°гөҪБЛјЖЛг»ъЙПЎЈДЗКұЈ¬ҙжҙўЖчәЬ№уЈ¬Т»Р©ҝЖС§јТИПОӘФЪГҝРРҪбОІјУБҪёцЧЦ·ыМ«АЛ·СБЛЈ¬јУТ»ёцҫНҝЙТФЎЈУЪКЗЈ¬ҫНіцПЦБЛ·ЦЖзЎЈ
UnixПөНіАпЈ¬ГҝРРҪбОІЦ»УРЎ°<»»РР>ЎұЈ¬јҙЎ°\nЎұЈ»WindowsПөНіАпГжЈ¬ГҝРРҪбОІКЗЎ° <»Шіө><»»РР>ЎұЈ¬јҙЎ°\r\nЎұЈ»MacПөНіАпЈ¬ГҝРРҪбОІКЗЎ°<»Шіө>ЎұЎЈТ»ёцЦұҪУәу№ыКЗЈ¬Unix/MacПөНіПВөДОДјюФЪWindowsАпҙтҝӘөД»°Ј¬ЛщУРОДЧЦ»бұдіЙТ»РРЈ»¶шWindowsАпөДОДјюФЪUnix/MacПВҙтҝӘөД»°Ј¬ФЪГҝРРөДҪбОІҝЙДЬ»б¶аіцТ»ёц^M·ыәЕ
windowsҙҙҪЁөДОДјюКЗ \n\rҪбКшөДЈ¬ ¶шlinuxЈ¬macХвЦЦunixАаПөНіКЗ\nҪбКшөДЎЈ
ЛщТФunixөДОДұҫөҪwindows»біцПЦ»»РР¶ӘК§ЈЁultraeditХвЦЦИнјюҝЙТФХэИ·К¶ұрЈ©Ј» ¶ш·ҙ№эАҙҫН»біцПЦ^MөД·ыәЕБЛ
WindowsөИІЩЧчПөНіУГөДОДұҫ»»РР·ыәНUNIX/LinuxІЩЧчПөНіУГөДІ»Н¬Ј¬WindowsПөНіПВКдИлөД»»РР·ыФЪUNIX/LinuxПВІ»»бПФКҫОӘЎ°»»РРЎұЈ¬¶шКЗПФКҫОӘ ^M Хвёц·ыәЕЈЁХвКЗLinuxөИПөНіПВ№ж¶ЁөДМШКвұкјЗЈ¬ХјТ»ёцЧЦ·ыҙуРЎЈ¬І»КЗ ^ әН M өДЧйәПЈ¬ҙтУЎІ»іцАҙөДЈ©ЎЈLinuxПВәЬ¶аОДұҫұајӯЖчЈЁГьБоРРЈ©»бФЪПФКҫХвёцұкјЗЦ®әуЈ¬І№ЙПТ»ёцЧФјәөД»»РР·ыЈ¬ТФұЬГвДЪИЭ»мВТЈЁЦ»КЗУГУЪПФКҫЈ¬І№ідөД»»РР·ыІ»»бРҙИлОДјюЈ¬УРЧЁГЕөДГьБоҪ«Windows»»РР·ыМж»»ОӘLinux»»РР·ыЈ©ЎЈ UNIX/LinuxПөНіПВөД»»РР·ыФЪWindowsПөНіөДОДұҫұајӯЖчЦР»бұ»әцВФЈ¬ХыёцОДұҫ»бВТіЙТ»НЕЎЈ
windows»»РРКЗ\r\nЈ¬К®БщҪшЦЖКэЦөКЗЈә0D0AЎЈ
LINUX»»РРКЗ\nЈ¬К®БщҪшЦЖКэЦөКЗЈә0A
ЛщТФФЪlinuxұЈҙжөДОДјюФЪwindowsЙПУГјЗКВұҫҝҙөД»°»біцПЦәЪөгЈ¬ОТГЗҝЙТФФЪLINUXПВУГГьБо°СlinuxөДОДјюёсКҪЧӘ»»іЙwinёсКҪөДЎЈ
unix2dos КЗ°СlinuxОДјюёсКҪЧӘ»»іЙwindowsОДјюёсКҪ
dos2unix КЗ°СwindowsёсКҪЧӘ»»іЙlinuxОДјюёсКҪЎЈ
linuxПВЙҫіэwindows»»РР·ы^M
OJЕРМвКұ·ўПЦТ»ёцОКМвЈәУГ%c¶БИлөДҙъВл¶ј»бұЁwaЎЈәуАҙ·ўПЦёъscanfУР№ШЎЈФЪlinuxПВК№УГ%c»б¶БөҪ\nәН\rБҪёцЧЦ·ыЎЈЛщТФРиТӘҪ«^MЈЁТІҫНКЗ\rЈ©ЧЦ·ыЙҫөф
Йҫіэ·Ҫ·ЁІ»ЙЩЎЈХТБЛТ»ёцұИҪПјтөҘөДЎЈ
ТӘҪ«a.txtАпөД^MИҘөфІўРҙИлb.txtЈ¬ФтК№УГИзПВЦёБоcat a.txt | tr -d "^M" > b.txt
ЧўТвЈәУпҫдЦРөД^MКЗНЁ№эctrl+V, ctrl+MКдИлөДЎЈМШЦё/rЧЦ·ы
unix ПВ»»РР·ыЦ»УР: \r
Dos ПВ»»РР·ыУРЈә\r\n
ҫЯМеөДЈ¬ \rөДascii ВлКЗЈә14
\nөДascii ВлКЗЈә10
AөДASCIIВлКЗ65Ј¬aөДASCIIВлКЗ97ЎЈ
ASCIIВлұнЦРЈ¬РЎРҙЧЦДёЕЕФЪҙуРҙЧЦДёөДәуГжЈ¬Т»ёцЧЦДёөДҙуРЎРҙКэЦөПаІо32Ј¬Т»°гЦӘөАҙуРҙЧЦДёөДASCIIВлКэЦөЈ¬Жд¶ФУҰөДРЎРҙЧЦДёөДASCIIВлКэЦөҫНЛгіцАҙБЛЈ¬КЗҙуРҙЧЦДёөДASCIIВлКэЦө+32ЎЈ
А©Х№ЧКБП
ФЪASCIIВлЦРЈ¬0Ў«31ј°127(№І33ёц)КЗҝШЦЖЧЦ·ы»тНЁРЕЧЁУГЧЦ·ыЈ¬ИзҝШЦЖ·ыЈәLFЈЁ»»РРЈ©ЎўCRЈЁ»ШіөЈ©ЎўFFЈЁ»»ТіЈ©ЎўDELЈЁЙҫіэЈ©ЎўBSЈЁНЛёс)ЎўBELЈЁПмБеЈ©өИЎЈ
НЁРЕЧЁУГЧЦ·ыЈәSOHЈЁОДН·Ј©ЎўEOTЈЁОДОІЈ©ЎўACKЈЁИ·ИПЈ©өИЎЈ
ASCIIЦөОӘ8Ўў9Ўў10 әН13 ·ЦұрЧӘ»»ОӘНЛёсЎўЦЖұнЎў»»РРәН»ШіөЧЦ·ыЎЈЛьГЗІўГ»УРМШ¶ЁөДНјРОПФКҫЈ¬ө«»бТАІ»Н¬өДУҰУГіМРтЈ¬¶ш¶ФОДұҫПФКҫУРІ»Н¬өДУ°ПмЎЈ
32Ў«126(№І95ёц)КЗЧЦ·ы(32КЗҝХёсЈ©Ј¬ЖдЦР48Ў«57ОӘ0өҪ9К®ёц°ўАӯІ®КэЧЦЎЈ
65Ў«90ОӘ26ёцҙуРҙУўОДЧЦДёЈ¬97Ў«122әЕОӘ26ёцРЎРҙУўОДЧЦДёЈ¬ЖдУаОӘТ»Р©ұкөг·ыәЕЎўФЛЛг·ыәЕөИЎЈ
Н¬Кұ»№ТӘЧўТвЈ¬ФЪұкЧјASCIIЦРЈ¬ЖдЧоёЯО»(b7)УГЧчЖжЕјРЈСйО»ЎЈ
ЛщОҪЖжЕјРЈСйЈ¬КЗЦёФЪҙъВлҙ«ЛН№эіМЦРУГАҙјмСйКЗ·сіцПЦҙнОуөДТ»ЦЦ·Ҫ·ЁЈ¬Т»°г·ЦЖжРЈСйәНЕјРЈСйБҪЦЦЎЈ | 




